
Mês passado, embarquei em uma jornada de aprendizado na Pós-Graduação em Ciência de Dados do IPOG. O primeiro módulo, “Introdução à Ciência de Dados”, nos desafiou a analisar os dados de uma empresa fictícia chamada Olsen Center. Em grupo, mergulhamos nos dados em busca de insights valiosos para o CMO da empresa.
Trabalho feito, mas, por não ter havido necessidade diante dos resultados obtidos, acabamos não realizamos uma análise RFM. O professor ensinou a fazê-la com o auxílio do Orange Data Mining e, como a curiosidade falou mais alto, decidi explorar essa técnica por conta própria.
Neste artigo, vou comentar brevemente o que é a análise RFM, como implementei essa análise no Orange Data Mining e os resultados que obtive.
O que é Análise RFM? (TL;DR style 😜)
A análise RFM é uma técnica de segmentação de clientes que utiliza três dimensões principais:
- Recência: há quanto tempo o cliente fez a última compra?
- Frequência: com que frequência o cliente compra?
- Valor Monetário: quanto o cliente gasta em suas compras?
Essa análise permite identificar grupos de clientes com comportamentos semelhantes, possibilitando a criação de estratégias de marketing mais eficazes. Por exemplo, clientes que compraram recentemente, compram com frequência e gastam muito são considerados clientes de alto valor e merecem atenção especial.
Implementação no Orange Data Mining
A Análise RFM é uma técnica bem bacana para entender o comportamento dos clientes e segmentá-los de forma eficaz. No entanto, a base de dados da Olsen Center que nos foi fornecida não continha informações detalhadas sobre os clientes finais. Em vez disso, tínhamos dados dos pedidos (orders) e das lojas (stores) onde esses pedidos foram feitos.
Dada a natureza da Olsen Center, onde as lojas atuam como pontos de venda e distribuição, podemos considerar as lojas como nossos “clientes” para fins de análise. Essa abordagem nos permitiria identificar as lojas mais valiosas e entender seus padrões de venda.
Os passos que segui para realizar a análise RFM estão ilustrados na seguinte imagem e detalhados na sequência.
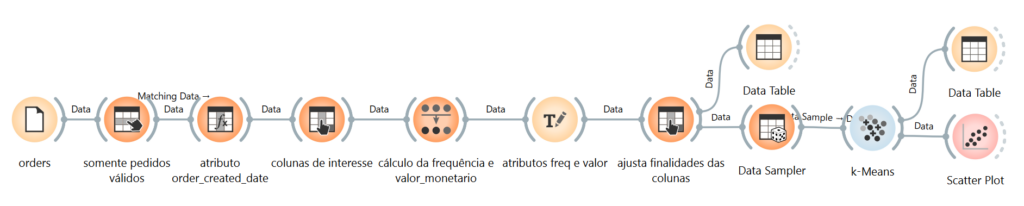
Carregamento dos dados
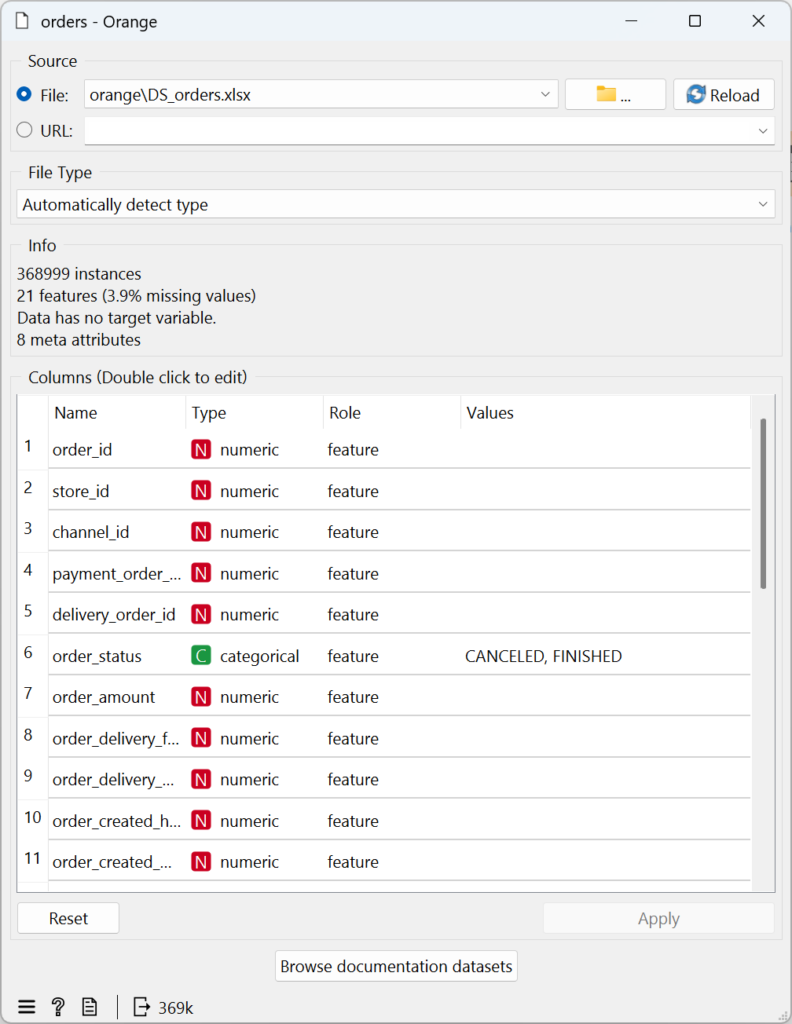
Para iniciar, carreguei os dados dos pedidos (orders) no Orange Data Mining:
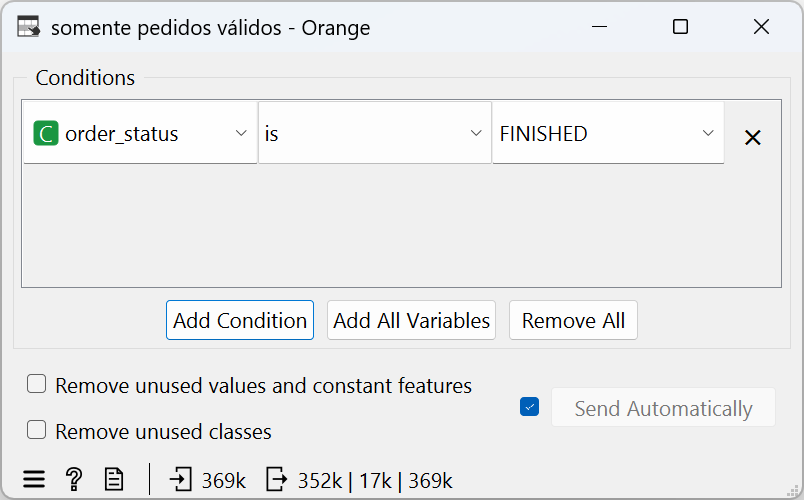
Filtragem dos pedidos cancelados
Em seguida, filtrei os pedidos cancelados (order_status == FINISHED) para garantir que apenas os pedidos concluídos fossem considerados na análise:
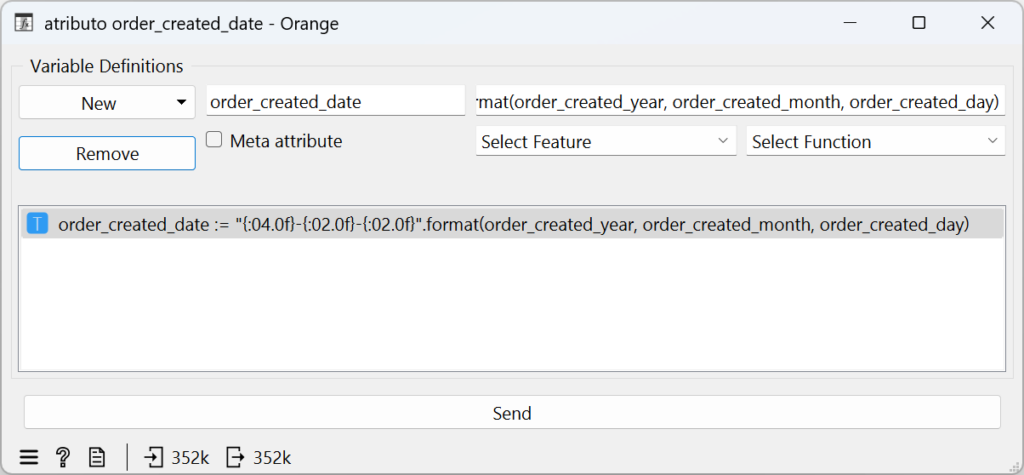
Criação do campo para Recência
A tabela original continha um campo de data não normalizado, mas também colunas separadas para dia, mês e ano. Para criar o campo de recência, juntei esses componentes no formato AAAA-MM-DD, resultando em um novo campo que chamei de order_created_date:
Seleção dos campos de interesse
Selecionei apenas os campos relevantes para a análise RFM:
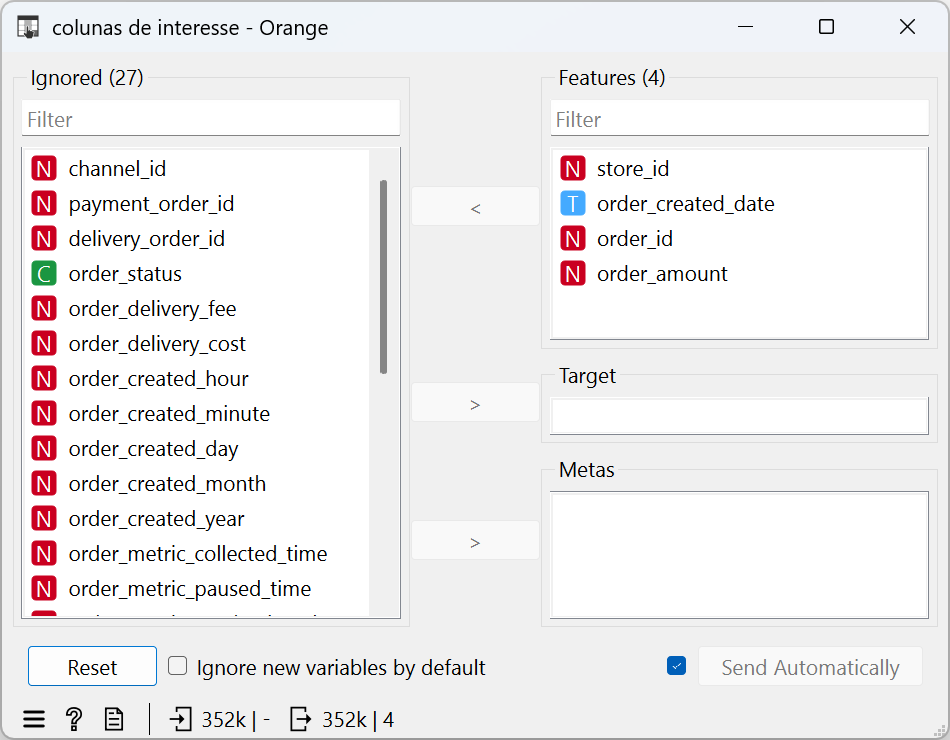
store_id: identificador da loja (nosso “cliente”).order_created_date: o campo que acabamos de criar e que indicará a recência.order_id: para calcular a frequência dos pedidos.order_amount: para calcular o valor total de vendas.
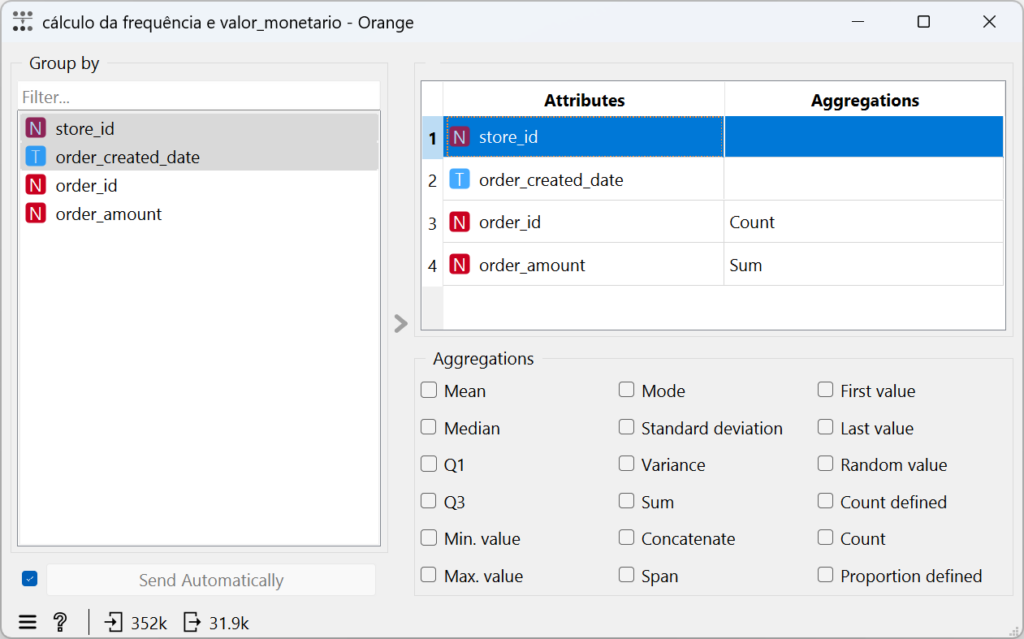
Cálculo da Frequência e Valor Monetário
Utilizei o componente “Group By” para calcular a frequência (número de pedidos por loja) e o valor monetário (total de vendas por loja) para cada loja e em cada data:
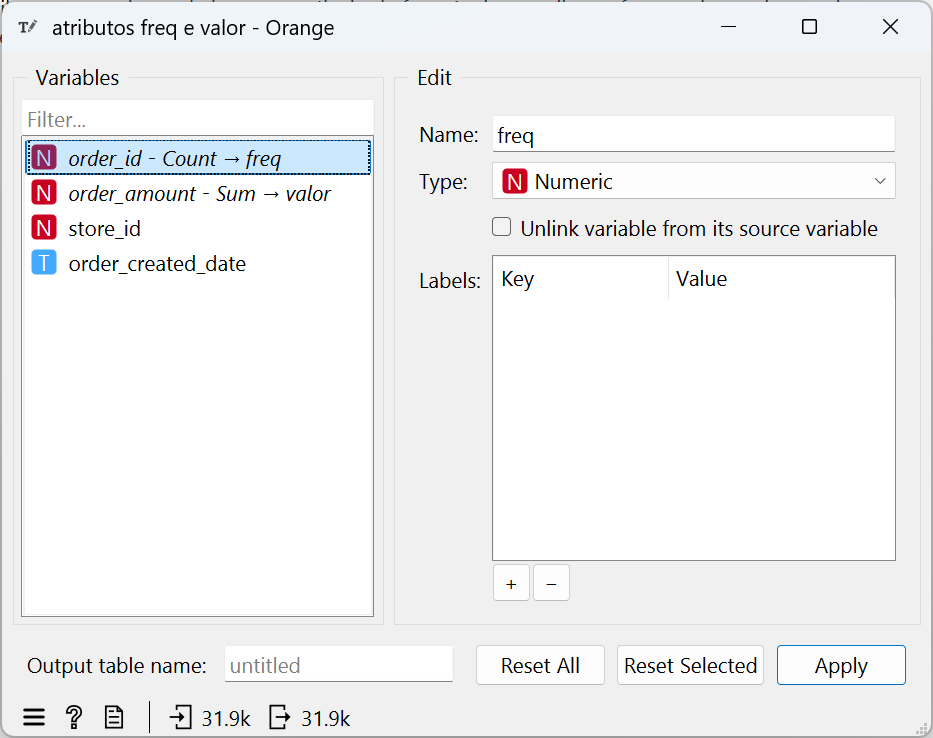
Renomeação e ajuste dos tipos de dados e das colunas
Para facilitar a análise, renomeei as colunas criadas pelo “Group By”:
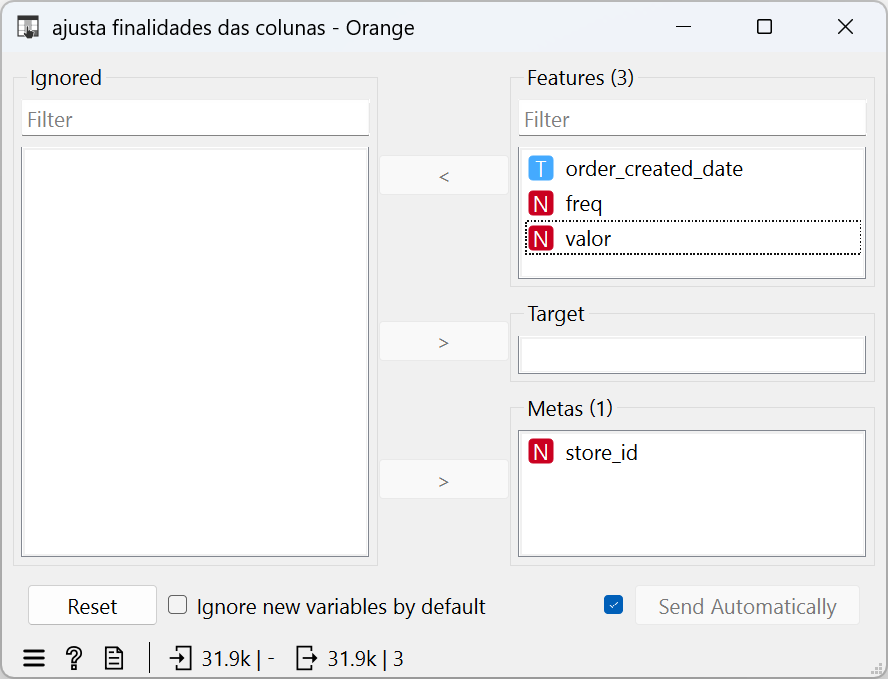
Além disso, utilizei mais um componente de seleção de colunas (“Select Columns”) para definir a finalidade de cada coluna – o importante aqui foi colocar o store_id como “Metas” para que ele não entrasse nos “cálculos” do algoritmo de clusterização:
Visualização dos dados preparados
No final, os dados preparados ficaram dessa forma:
Amostragem dos dados
Para otimizar o desempenho do algoritmo de clusterização, fiz uma amostra aleatória de 5000 dados, que é o que ele recomenda para poder calcular os “Silhouette scores”:
Clusterização com K-Means
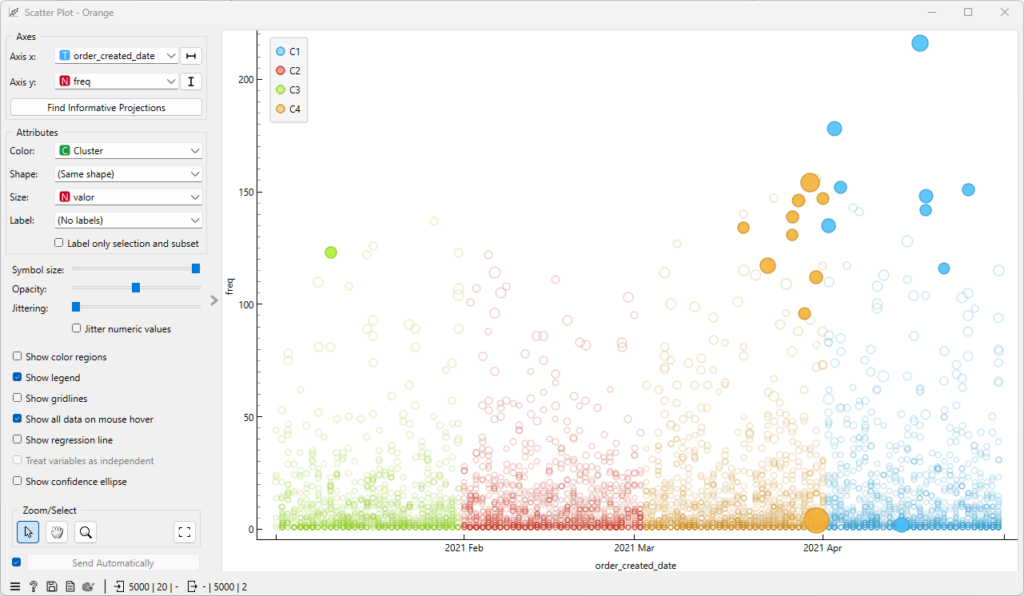
Com os dados preparados, utilizei o algoritmo de clusterização K-Means para segmentar as lojas em diferentes grupos com base em seus valores de RFM. O “Silhouette score” indicava que 3 classes era um bom número, mas achei que 4 classes dividia melhor os conjuntos (e tinha um score bem parecido):
Os resultados da clusterização foram apresentados em um gráfico, permitindo identificar os diferentes segmentos de lojas com base em seus padrões de recência, frequência e valor monetário.
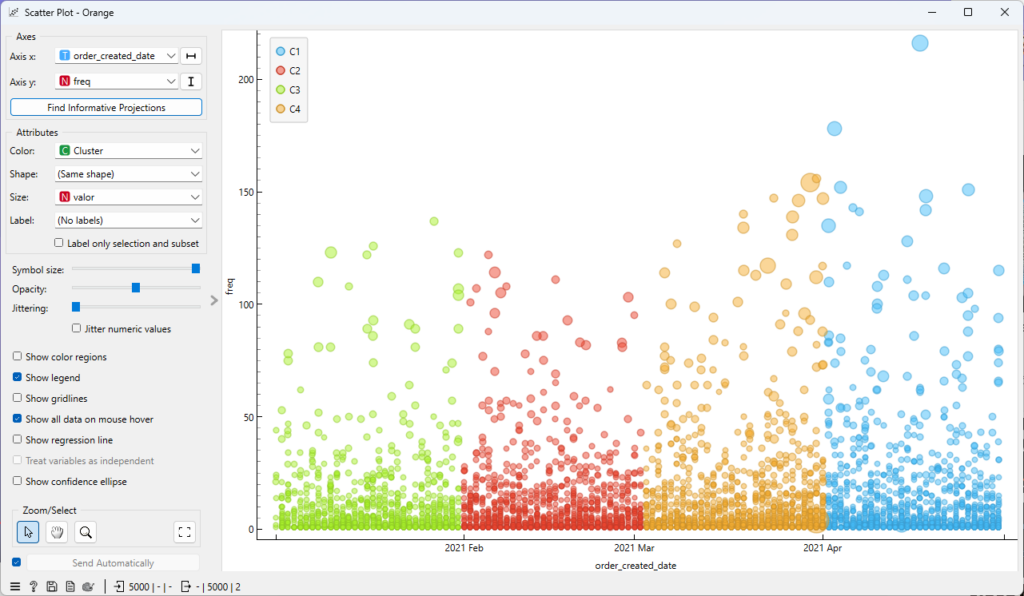
Resultados
A análise RFM das lojas da Olsen Center, realizada com o auxílio do Orange Data Mining, permitiu identificar diferentes segmentos de lojas com base em seus padrões de vendas. Esses insights podem ser utilizados para direcionar estratégias de marketing mais eficazes e aumentar o valor das lojas para a empresa.
Adicionalmente, selecionei as “top 20 maiores vendas”, mostrando mais uma camada de informações que podem auxiliar no direcionamento das estratégias:
Foi possível perceber que essa técnica é uma ferramenta interessante para entender o comportamento dos clientes e segmentá-los de forma eficaz. Com o auxílio do Orange Data Mining, essa análise se torna ainda mais acessível e fácil de implementar.
Para constar, além de várias ideias (e dúvidas) que foram surgindo conforme ia fazendo essa análise, também realizei algumas outras que não mostrei aqui:
- Adicionei as informações de cada loja (estado, latitude e longitude), de forma que foi possível filtrar por estado e também mostrar as informações em um mapa (apesar de parecer muito interessante visualmente, não achei que agregou alguma informação útil).
- Também fiz a análise RFM nas tabelas de
drivers,hubsechannels. Mas, para não ficar um artigo longo só mostrei a dasstores. De qualquer forma, com o andar do curso, pretendo fazer essas análises em Python lá no Kaggle! 😉
Se você gostou deste artigo, compartilhe suas dúvidas e sugestões nos comentários abaixo!
